Building an LLM from scratch-conceptual notes
What is an LLM?
An LLM is a neural network designed to understand, generate and respond to human like text. It's essentially a deep neural network trained on massive amounts of text data. Its called "large" number of parameters as well as the huge size of the dataset that is used for optimizing what essentially is, the next word in a sequence of words.
Next word prediction is a sensible approach because it taken in the inherent sequential nature of language to train models with context, structure and relationships within text. This is possible because of the transformer architecture, which allows these models to pay selective attention to different parts of the input when making predictions, allowing thing to handle and the nuances and specificities of the human language.
Stages of Building and Using LLMs
Reasons for a Custom Built LLM(Something tailored for a specific task or domain):
- Potential to outperform general purpose LLMs like ChatGPT
- Data Privacy
- Smaller custom LLMs can run locally on customer devices(kind of the goal with the new Siri and is a part of Apple's research)
- Lower latency and reduce server costs
- Complete autonomy and customization allowing modifications and updates to the model as needed Process of Creating an LLM The general process of creating an LLM has two main steps:
- pretraining: Training on a large and diverse corpus/dataset to develop a broad understanding of the language itself. These models are generally called foundational models. This data is generally unlabelled since LLMs use self-supervised learning where the model generates its own labels from the input data
- finetuning: Taking these foundational models and again training it on a narrower(labelled) dataset that is more specific to a certain task or domains
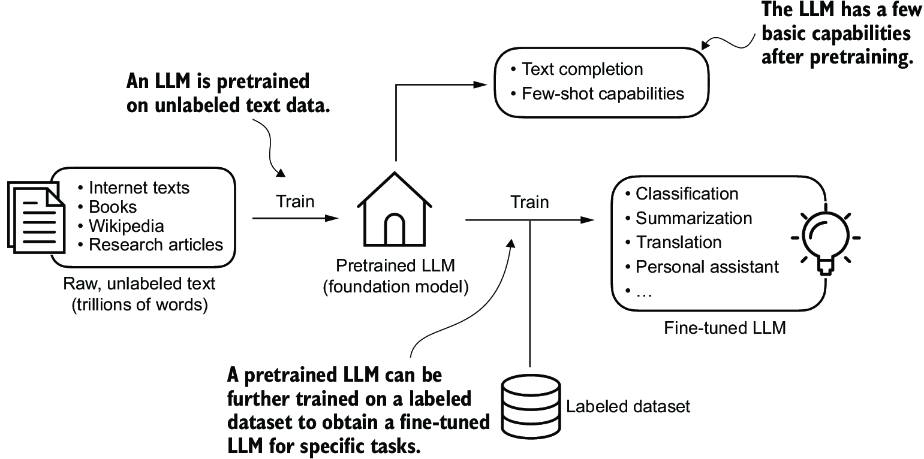
There are two main types of finetuning:
- Instruction fine tuning: The labelled dataset consists of more instruction and answer based pairs such as a query to translate a text along with the correct translation.
- Classification Finetuning: The labelled dataset consists of texts and associated labels, for instance to classify emails as spam vs non spam
Introducing the Transformer Architecure
This is based on the Attention is all you need paper.
The transformer consists of two main parts
- Encoder(Left Side of the diagram below): processes the raw text as input and produces an embedding (numerical representation)
- Decoder(Right Side of the diagram below): Takes in the embeddings to sequentially generate text one word at a time.
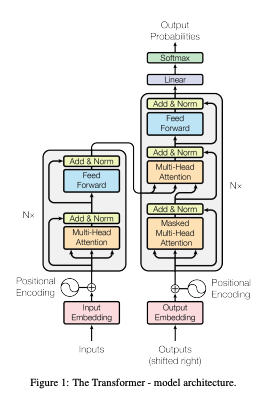
These layers are connected by multiple layers connected by a self-attention mechanism(Essentially mapping out a query as a key value pair to an output where query, key, value and output are all vectors)
Pivot: Attention Mechanisms
Scaled Dot Product Attention: Attention is computed on a set of queries simultaneously packed into a matrix Q. The keys and values have their own matrices K and V. The outputs are then calculated as follows:
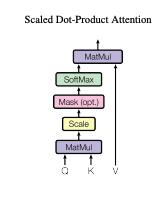
query @ key --> scaled by 1/sqrt(dimension of keys) --> softmax --> @ values --> output
Additive attention is the same as the formula above, just without the scaling factor and instead uses a feed forward network with a single layer
Multi-head Attention:
The queries keys are values are projected(linear projection is a simplification method to make calculations easier by multiplying them with weights essentially) h times with different learned linear projections to , , and respectively. The attention function is then done in parallel and then concatenated and then projected to get the final values.
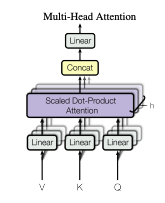
where and the projections are parameter matrixes
Closer look at the GPT architecture
GPT Paper for reference
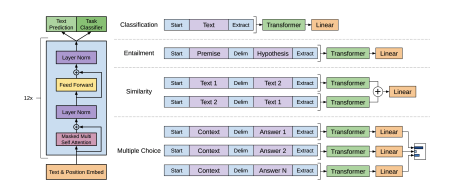 GPT-3 is a scaled up version of this model with more parameters trained on methods from https://arxiv.org/abs/2203.02155
GPT-3 is a scaled up version of this model with more parameters trained on methods from https://arxiv.org/abs/2203.02155
This essentially focuses only on the decoder part of the transformer architecture. Since text generation happens one word at a time, it is considered a type of autoregressive models since it incorporates their previous outputs as inputs for future predictions.
This architecture is also much larger than the original transformer model which repeated the encoder and decoder blocks 6 times as opposed to 96 transformer layers and 175 billion params for GPT-3
This model surprisingly was able to achieve the transformer's original goal of text translation which it was not expected to do. This phenomenon is called emergent behavior where the capability isnt explicitly taught during training but instead emerges as a natural consequence of the model's exposure to vast quantities of data in different contexts.
Stages of Implementation of an LLM
- Implementing architecture and data prep process
- Pretraining
- Finetuning